Encoding Categorical Variables in Python
- Ekta Aggarwal

- Aug 27, 2022
- 3 min read
In this tutorial we will learn how to encode or convert categorical variables in numbers.
Categorical variables are generally of 2 types: Nominal and Ordinal
1. Ordinal Variables are those which have a proper order.
Eg. High , Medium, Low - Here high has the highest priority while low has the least priority High > Medium > Low.
Similarly, Excellent > Average> Poor- Here Excellent is considered as the best while Poor having the least priority.
Such variables which exhibit an order are ordinal variables.
2. Nominal variables are those which do not have any order: eg. Weather: Sunny, Rainy, Winter - these 3 weathers do not have any priority
There are different methods to encode these variables in Python.
Let us firstly load pandas
import pandas as pdEncoding Ordinal Variables
For encoding ordinal variables, we can use sklearn's LabelEncoder. Let us initialise our LabelEncoder as le
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()Let us create a dataframe where we have Dependents column taking values 0,1, 2, 3+ . Here we have 3+ > 2 > 1 > 0 . Thus it is an ordinal variable.
df = pd.DataFrame({"Dependents" : ['0','0','1','1','2','2','3+']})
print(df)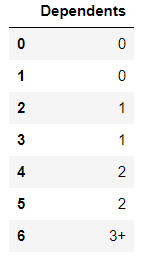
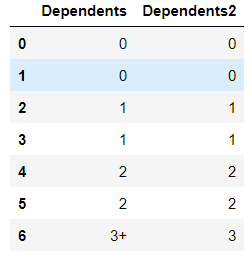
Using fit_transform we can create a new column named Dependents2, where it has encoded our Dependents column in our df.
df["Dependents2"] = le.fit_transform(df["Dependents"])
print(df)In the output below you can see that it has automatically considered 3+ as 3.
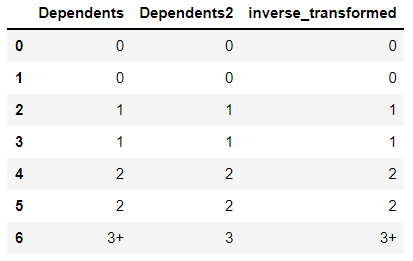
Suppose if you want your original column back then you can use inverse_transform function in your encoded column Dependents2.
df['inverse_transformed'] = le.inverse_transform(df.Dependents2)
print(df)In the output you can see that it has converted 3 to 3+ in inverse_transformed columns.
Note: LabelEncoder encodes categorical variables only in ascending order.
Let us consider another dataframe where we have Sales_Status column talking values as : High, Medium and Low. Since High > Medium > Low , therefore it is an ordinal variable.
df = pd.DataFrame({"Sales_Status" : ['High','High','Medium','Medium','Low','Low','High']})
print(df)
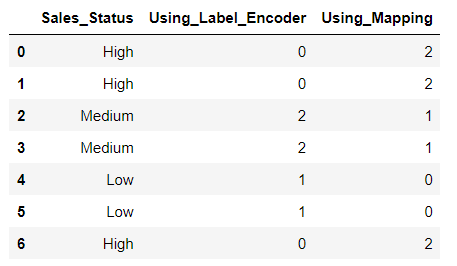
If we apply LabelEncoder on Sales_Status column then we can see that It has mapped High as 0, Low as 1 and Medium as 2. This is because LabelEncoder is encoding these variables on the basis of alphabetical order.
df["Using_Label_Encoder"] = le.fit_transform(df["Sales_Status"])
print(df)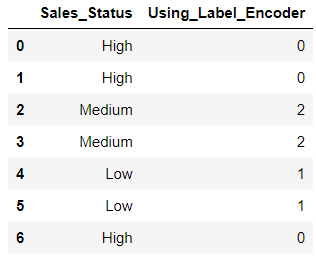
However, this is incorrect as we know this High should get the highest number. Thus, We cannot use LabelEncoder in this situation. For this we create a dictionary named Ratings which will be used for mapping the correct labels.
Ratings = {'Low' : 0, 'Medium' : 1, 'High' : 2}Now using map function we can map our dictionary Ratings to our Sales_Status column.
df['Using_Mapping'] = df.Sales_Status.map(Ratings)
print(df)You can see in the output below that the last column Using_Mapping has now applied the correct mapping to Sales_Status column.
Encoding Nominal Variables
Let us consider a dataframe which has different Departments: Consulting, Technology and Outsourcing. Here clearly there is no order in these departments, thus we cannot use label encoder.
We can create 3 columns for each of them namely: Dep_consulting, dep_technology and dep_outsourcing.
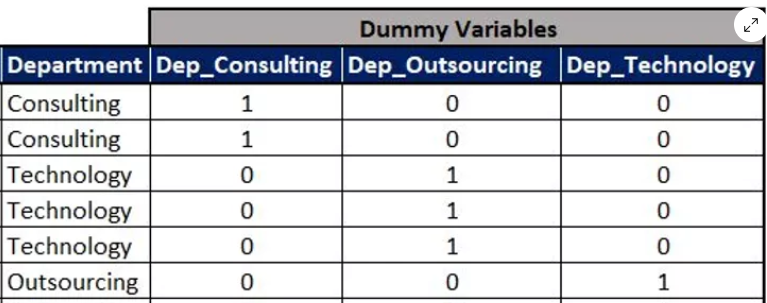
When the department is consulting then Dep_consulting = 1 and other 2 variables are 0.
Similarly for technology department Dep_technology = 1 and other 2 will be 0.
Lastly, for outsourcing department dep_outsourcing = 1 and others as 0.
Note: It can never happen that there can be more than one 1 in a set of dummy variables. In a single row for dummy variables there can be at most one 1.
When categorical variables can be expressed in 1-0 notation - these are called dummy variables.
Now let us create our DataFrame
data2 = pd.DataFrame({'Department': ['Consulting','Technology','Consulting','Consulting','Outsourcing']})
print(data2)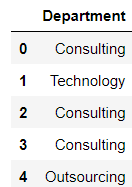
Using pandas' get_dummies( ) function we can create dummy variables with a single line of code.
For each department name have added a prefix "Dep"
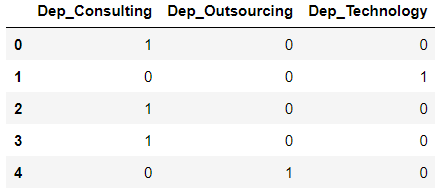
get_dummies( ) only creates dummy variables. To append it in our data we use pandas' concat function:
Let us firstly save our dummy variables in a dataset.
dummy_variables = pd.get_dummies(data2.Department,prefix = "Dep")We now concatenate our original data using pd.concat( ) , by defining axis = 1 or axis = "columns" we are telling Python to add the columns horizontally (and not append them as rows).
pd.concat([data2,dummy_variables],axis =1)
#alternatively
pd.concat([data2,dummy_variables],axis = "columns")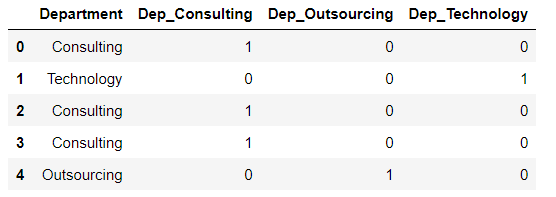
When Dep_Consulting = 1 and Dep_Technology is 0 then it is self-implied that dep_outsourcing will be 0. Thus in this case we only need 3-1 = 2 dummy variables. We can drop the first column by specifying drop_first = True.
dummy_variables = pd.get_dummies(data2.Department,prefix = "Dep",drop_first=True)
pd.concat([data2,dummy_variables],axis = "columns")



Comments