Merging data in SAS
- Ekta Aggarwal

- Jan 22, 2021
- 7 min read
Datasets in SAS can be merged using :
PROC SQL
Merge statement.
In this tutorial we shall learn how to join or merge datasets in SAS using MERGE statement.
To understand how PROC SQL and how joins work in SQL refer to the following tutorials:
PROC SQL in SAS
Let us firstly define our LIBNAME as follows:
libname mylib '/home/u58392927/My_datasets';There are majorly 5 types of joins in SAS using MERGE statement:
In this tutorial we shall be covering all 5 of them in detail along with
Dataset
For this tutorial we shall make use of 2 datasets: DATA and DATA2.
DATA mylib.DATA;
INPUT Department : $30. Months $ No_of_cases;
CARDS;
Cardiology Jan 7713
Cardiology Feb 243
Cardiology Mar 543
E&A Jan 772
E&A Feb 443
E&A Mar 82
;
RUN;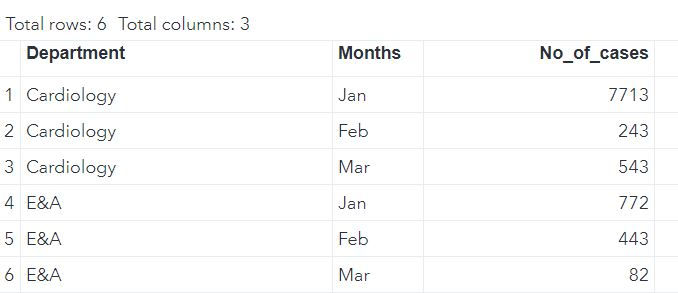
DATA mylib.DATA2;
INPUT Department : $30. Months $ No_of_deaths;
CARDS;
Cardiology Jan 23
Cardiology Feb 21
E&A Jan 42
Neurology Jan 12
;
RUN;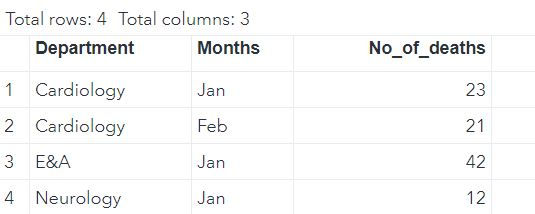
THINGS TO KEEP IN MIND WHILE USING MERGE STATEMENT.
Before merging using MERGE statement one must keep in minds that the common key* for the datasets MUST be sorted using PROC SORT. (Common key refers to the columns on which the join needs to be made.)
Column names for common keys should be same in both the datasets! If they are not then need to be renamed first.
Sorting our data
Our common keys in both the datasets are Department and Months thus we are sorting our data by them.
PROC SORT DATA = MYLIB.DATA;
BY DEPARTMENT MONTHS;
RUN;PROC SORT DATA = MYLIB.DATA2;
BY DEPARTMENT MONTHS;
RUN;Syntax:
DATA new_merged_dataset;
MERGE data1 (in =alias1) data2 (in = alias2);
BY common keys;
RUN;providing alias names are optional but it is better to provide them as they provide ease while referring to the tables.
Outer join or Full join
By default SAS executes outer join or full join.
Full join takes all the records from both the tables (specified in MERGE statement). Missing values get generated if a record is available in only one table.
In the following query we have provided alias names as a1 and a2 for DATA and DATA2 respectively.
DATA MYLIB.MERGED;
MERGE MYLIB.DATA(in = a1) MYLIB.DATA2 (in = a2);
BY DEPARTMENT MONTHS;
RUN;Note that in both the data we have 7 unique (DEPARTMENT - MONTH) combinations thus our resultant outer join has 7 rows.
Cardiology - Mar , E&A Feb and E&A Mar - They were not present in DATA2 hence No_of_deaths is missing for them.
Similarly, Neurology - Jan - It was not present in DATA1 thus No_of_cases is missing.
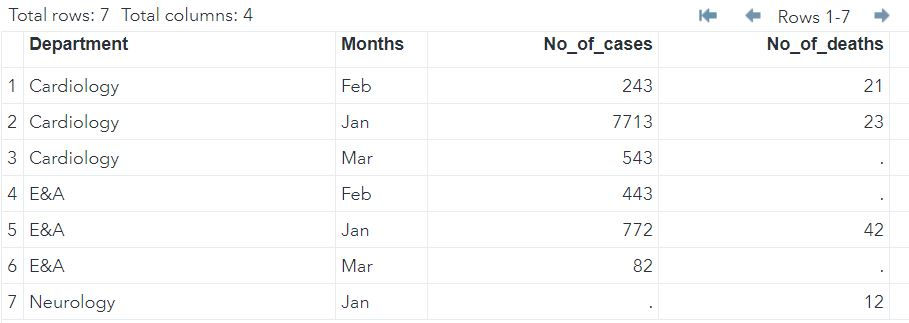
Left join
Left join takes all the records from left table (specified in MERGE and IF statement) irrespective of availability of record in right table (not specified in IF statement).
If the record is not available in the right table then missing values get generated for such records.
In the following query my left table is a1 and right table is a2;
Note: There is one extra statement: IF a1; which indicates that all the records from a1 should be there in resultant table irrespective of their availability in a2.
DATA MYLIB.MERGED;
MERGE MYLIB.DATA(in = a1) MYLIB.DATA2 (in = a2);
BY DEPARTMENT MONTHS;
IF a1;
RUN;In the left table data we have 6 rows thus our resultant LEFT join has 6 rows.
Cardiology - Mar , E&A Feb and E&A Mar - They were not present in DATA2 hence No_of_deaths is missing for them.
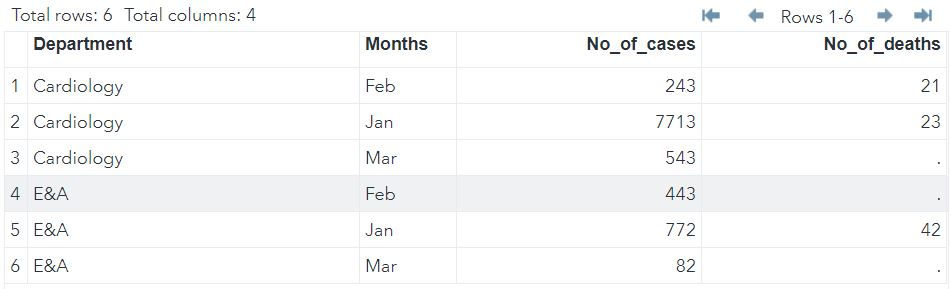
Right join
Right join takes all the records from right table (specified in MERGE and IF statement) irrespective of availability of record in left table (not specified in IF statement).
If the record is not available in the left table then missing values get generated for such records.
In the following query my left table is a1 and right table is a2;
Note: There is one extra statement: IF a2; which indicates that all the records from a2 should be there in resultant table irrespective of their availability in a1.
DATA MYLIB.MERGED;
MERGE MYLIB.DATA(in = a1) MYLIB.DATA2 (in = a2);
BY DEPARTMENT MONTHS;
IF a2;
RUN;In the right table data we have 4 rows thus our resultant RIGHT join has 4 rows.
Neurology - Jan - It was not present in DATA1 thus No_of_cases is missing.
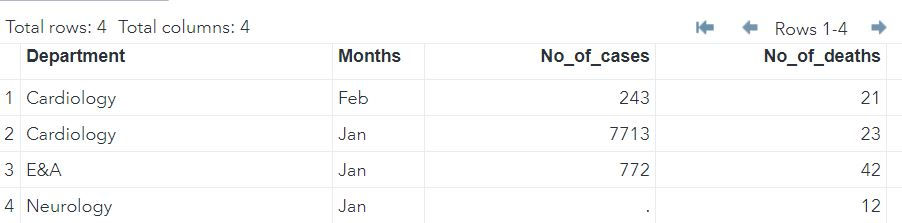
Inner Join:
Inner Join takes common elements in both the tables and join them.
To indicate an inner join in SAS we need to right IF a1 and a2 : which means take only those Department - Month combinations which are present in both the tables.
DATA MYLIB.MERGED;
MERGE MYLIB.DATA(in = a1) MYLIB.DATA2 (in = a2);
BY DEPARTMENT MONTHS;
IF a1 and a2;
RUN;There are only 3 common Department - Month combinations in both the data thus our output has only 3 rows.
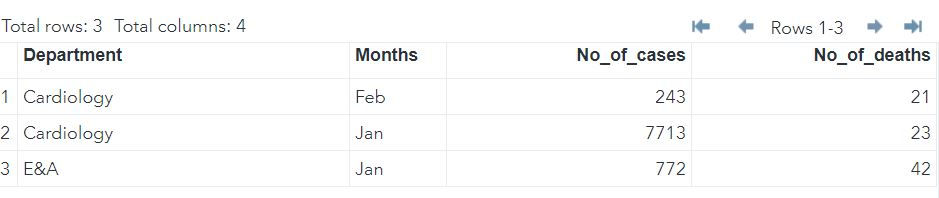
Anti Join:
Anti join comprises of those records which are present in one table but not in other.
To indicate an anti-join we write:
IF NOT alias_name; Which means get those records which are present in all the tables except the table whose alias_name is mentioned in IF statement.
Anti join 1:
In the following code we are fetching those rows which belong to DATA2 and are not present in DATA1.
DATA MYLIB.MERGED;
MERGE MYLIB.DATA(in = a1) MYLIB.DATA2 (in = a2);
BY DEPARTMENT MONTHS;
IF not a1;
RUN;Neurology-Jan combination is present in Data2 but is absent in Data1.

Anti join 2:
In the following code we are fetching those rows which belong to DATA1 and are not present in DATA2.
DATA MYLIB.MERGED;
MERGE MYLIB.DATA(in = a1) MYLIB.DATA2 (in = a2);
BY DEPARTMENT MONTHS;
IF not a2;
RUN;Following 3 combinations are present in Data1 but are not available in data2.

Varying Lengths of common keys
Suppose Department column in both the tables have different lengths then it might happen that the department name can get truncated in the output table. To avoid that we define a LENGTH statement and specify the length for the newly merged data.
DATA MYLIB.MERGED;
LENGTH DEPARTMENT $50.;
MERGE MYLIB.DATA(in = a1) MYLIB.DATA2 (in = a2);
BY DEPARTMENT MONTHS;
RUN;Extra common columns are available which are not primary key
To understand this scenario let us create 2 new datasets DATA and DATA2 where there are 3 common columns: Department, Months and No_of_Doctors but we are only joining by Department and Months - what will MERGE statement do the column: No_of_doctors?
DATA mylib.DATA;
INPUT Department : $30. Months $ No_of_cases No_of_doctors;
CARDS;
Cardiology Jan 7713 50
Cardiology Feb 243 24
E&A Jan 772 25
E&A Feb 443 64
;
RUN;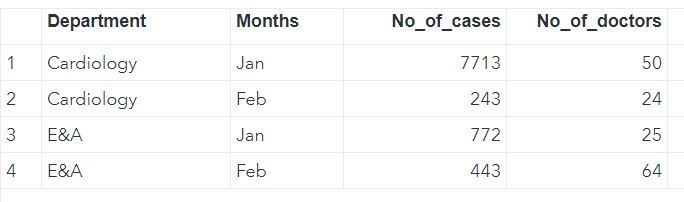
DATA mylib.DATA2;
INPUT Department : $30. Months $ No_of_deaths No_of_doctors;
CARDS;
Cardiology Jan 23 100
Cardiology Feb 21 134
E&A Jan 42 35
Neurology Jan 12 47
;
RUN;
Let us firstly sort our data by common keys - by which we have to merge them.
Note: We are not sorting no_of_doctors.
PROC SORT DATA = MYLIB.DATA;
BY DEPARTMENT MONTHS;
RUN;PROC SORT DATA = MYLIB.DATA2;
BY DEPARTMENT MONTHS;
RUN;Let us do an outer join for the same:
DATA MYLIB.MERGED;
MERGE MYLIB.DATA(in = a1) MYLIB.DATA2 (in = a2);
BY DEPARTMENT MONTHS;
RUN;In the resultant output SAS, for the common columns which are not used for merging (No_of_doctors in our case) , if a value is present in table 2 then SAS keeps that value, otherwise from table 1.
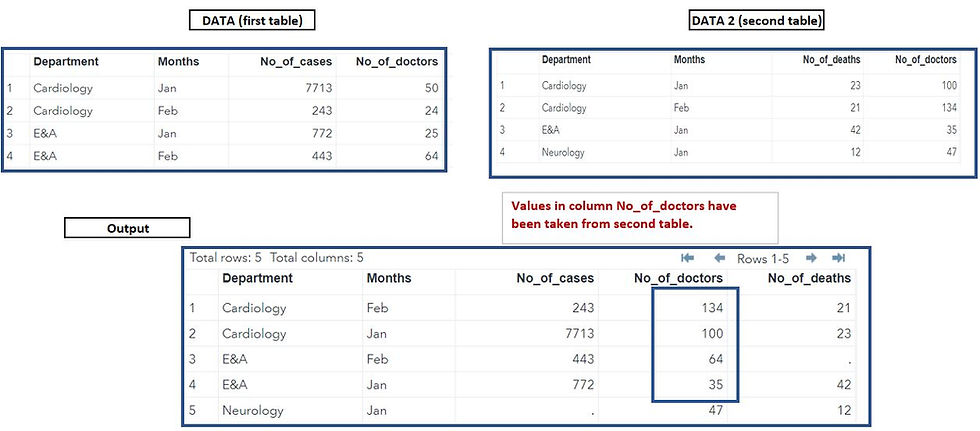
One to many mapping
Suppose one of our data (let us say first table) has unique records but in the second table we have multiple records for the common keys then we shall learn how SAS deals with such cases while merging.
To understand this scenario let us create 2 new datasets DATA and DATA2 where there are only one common column: Department. (We do not wish to join by Month)
DATA mylib.DATA;
INPUT Department : $30. Months $ No_of_cases;
CARDS;
Cardiology Jan 7713
E&A Jan 772
;
RUN;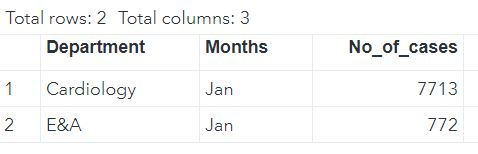
DATA mylib.DATA2;
INPUT Department : $30. Months $ No_of_deaths;
CARDS;
Cardiology Jan 23
Cardiology Feb 21
E&A Jan 42
E&A Feb 39
Neurology Jan 12
;
RUN;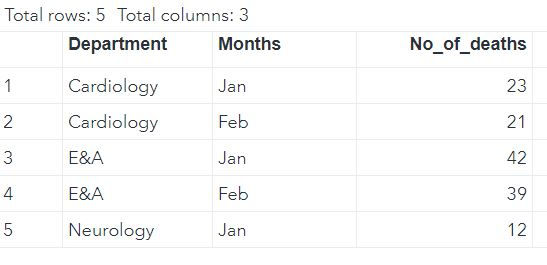
Let us sort our data by common key to be used for merging (i.e. Department)
PROC SORT DATA = MYLIB.DATA;
BY DEPARTMENT;
RUN;PROC SORT DATA = MYLIB.DATA2;
BY DEPARTMENT;
RUN;Let us do an outer join for the same:
DATA MYLIB.MERGED;
MERGE MYLIB.DATA(in = a1) MYLIB.DATA2 (in = a2);
BY DEPARTMENT;
RUN;Understanding the output:
In first table, Department column had unique values (but had month Jan) while 2nd table had duplicate values for department because we have 2 months: Jan and Feb.
Thus SAS has utilized the values from Cardiology (Jan month) from first table to fill Cardiology in second table (irrespective of the month). (Remember - We have not joined by months - we have joined our tables only by department)
Similarly SAS has used E&A's No_of_cases from first table and have filled the values for second table (not taking month into consideration)
Since no information about No_of_cases in Neurology is available in table 1 thus they are missing in the output/

Many to many mapping
If it were SQL, for many to many mapping we expect a cartesian join (i.e. a cross product) as an output but SAS returns maximum no. of duplicates as an output in case of multiple occurrences. i.e.
if 1 occurs 5 times in table 1 and 3 times in table 2 then in the resultant output SAS will return 5 rows for 1 (i.e. maximum time 1 has occurred in either of the datasets) while SQL will result in 10 (5*2) rows denoting a cartesian product.
Thus if some one is expecting a cartesian product as an output in SAS then THEY SHOULD NOT use MERGE statement. To get a cartesian product they should join using PROC SQL.
Let us take 2 new data where we are joining them by Department which has multiple repetitions in both the tables:
DATA mylib.DATA;
INPUT Department : $30. Months $ No_of_cases;
CARDS;
Cardiology Jan 7713
Cardiology Feb 5432
E&A Jan 772
;
RUN;
DATA mylib.DATA2;
INPUT Department : $30. Months $ No_of_deaths;
CARDS;
Cardiology Jan 23
Cardiology Feb 21
Cardiology Mar 49
E&A Jan 42
E&A Feb 39
Neurology Jan 12
;
RUN;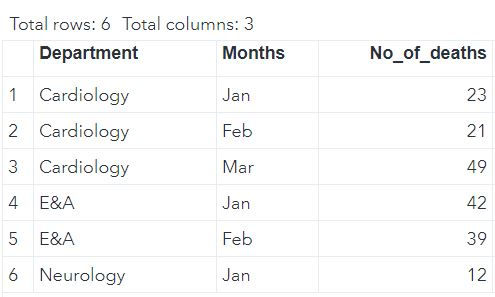
Let us sort our data by the keys which we want to merge our data on (i.e. Department)
PROC SORT DATA = MYLIB.DATA;
BY DEPARTMENT;
RUN;PROC SORT DATA = MYLIB.DATA2;
BY DEPARTMENT;
RUN;Let us perform an outer join
DATA MYLIB.MERGED;
MERGE MYLIB.DATA(in = a1) MYLIB.DATA2 (in = a2);
BY DEPARTMENT;
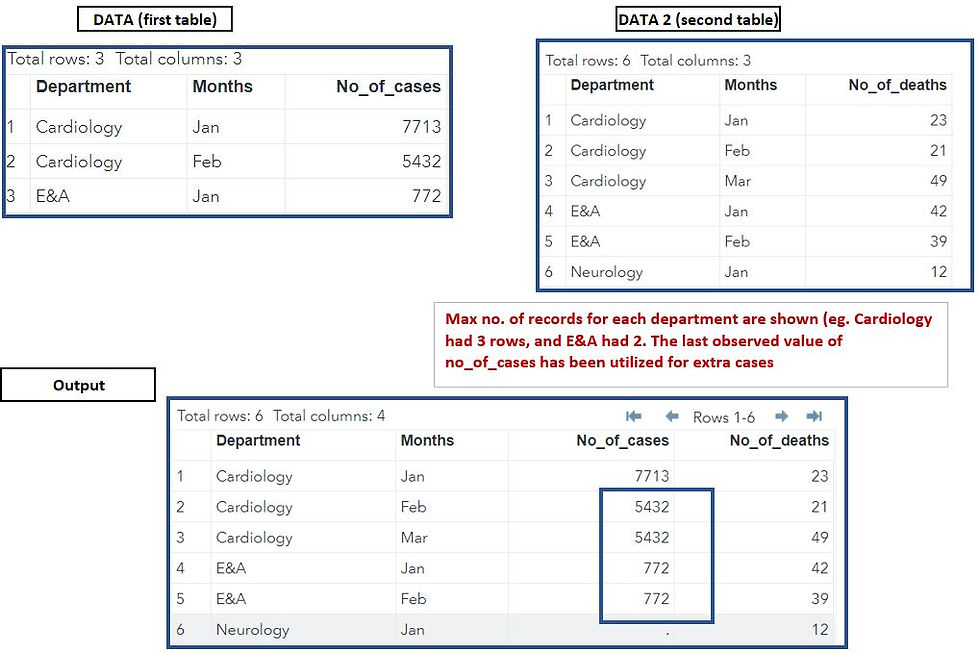
RUN;Understanding the output:
In first table, Cardiology Department had multiple values while 2nd table had duplicate values for Cardiology and E&A.
Cardiology department : Maximum occurrence of Cardiology department is 3 (in table 2) thus in the output we will have 3 rows (maximum no. of duplicates) and now for Cardiology Mar - it has utilized last processed value for Cardiology (i.e. Cardiology Feb i.e. 5432 cases)
E&A department: Maximum occurrence of E&A department is 2 (in table 2) thus in the output we will have 2 rows. For E&A Feb- it has leverages last processed value for E&A(i.e. E&A Jan i.e. 772 cases)
Neurology : Since Neurology department had no information in first table thus no_of_cases are missing for this.
Comments