Creating dummy variables in Python
- Ekta Aggarwal

- Jan 28, 2021
- 2 min read
In this tutorial we will learn what are dummy variables and how to create them.
What are dummy variables?
Let us consider the data where we have employee information and the department they are working for. Since department is a categorical variable thus we can denote them in a 1 - 0 format.
Suppose we have 3 departments: consulting, technology and outsourcing. We can create 3 columns for each of them namely: Dep_consulting, dep_technology and dep_outsourcing.

When the department is consulting then Dep_consulting = 1 and other 2 variables are 0.
Similarly for technology department Dep_technology = 1 and other 2 will be 0.
Lastly, for outsourcing department dep_outsourcing = 1 and others as 0.
Note: It can never happen that there can be more than one 1 in a set of dummy variables. In a single row for dummy variables there can be at most one 1.
When categorical variables can be expressed in 1-0 notation - these are called dummy variables.
Creating dummy variables in Python
Dataset:
In this tutorial we will make use of following CSV file:
Let us read our file using pandas' read_csv function. Do specify the file path where your file is located:
import pandas as pd
mydata = pd.read_csv("C:\\Users\\Employee_info.csv")Let us create a copy of our dataset as data1.
data1 = mydata.copy()Method 1: Using map( ) function we can create a mapping between our variable and new value.
We need to create 3 dummy variables manually using map( ) function
For consulting dummy , map function creates a mapping that when department is consulting the value will be 1 and for other 2 departments it will be 0.
In a similar fashion other 2 dummy variables can be created.
data1['Consulting Dummy'] = data1.Department.map({"Consulting" : 1,"Technology":0, "Outsourcing" : 0})
data1['Outsourcing Dummy'] = data1.Department.map({"Consulting" : 0,"Technology":0, "Outsourcing" : 1})
data1['Technology Dummy'] = data1.Department.map({"Consulting" : 0,"Technology":1, "Outsourcing" : 0})data1.head()
Drawback:
Suppose we have a categorical variable with 50 categories then creating dummy variables with map would be too cumbersome and mundane. To mitigate this we have pandas' get_dummies( ) function!
Method 2: Using pandas' get_dummies( ) function we can create dummy variables with a single line of code.
Let us create another copy of our data
data2 =mydata.copy()Using pandas' get_dummies( ) function we can create dummy variables with a single line of code.
For each department name have added a prefix "Dep"
pd.get_dummies(data2.Department,prefix = "Dep")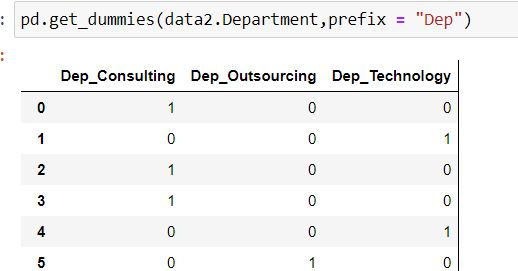
get_dummies( ) only creates dummy variables. To append it in our data we use pandas' concat function:
Let us firstly save our dummy variables in a dataset.
dummy_variables = pd.get_dummies(data2.Department,prefix = "Dep")We now concatenate our original data using pd.concat( ) , by defining axis = 1 or axis = "columns" we are telling Python to add the columns horizontally (and not append them as rows).
pd.concat([data2,dummy_variables],axis = 1)
#alternatively
pd.concat([data2,dummy_variables],axis = "columns")
When Dep_Consulting = 1 and Dep_Technology is 0 then it is self-implied that dep_outsourcing will be 0. Thus in this case we only need 3-1 = 2 dummy variables. We can drop the first column by specifying drop_first = True.
dummy_variables = pd.get_dummies(data2.Department,prefix = "Dep",drop_first=True)
pd.concat([data2,dummy_variables],axis = "columns")



Comments