Setting and filtering index in Python
- Ekta Aggarwal

- Jan 29, 2021
- 2 min read
In this tutorial we will learn about setting index in a dataframe and filtering the data using index.
Dataset:
In this tutorial we will make use of following CSV file:
Let us read our file using pandas' read_csv function. Do specify the file path where your file is located:
import pandas as pd
mydata = pd.read_csv("C:\\Users\\Employee_info.csv")mydata.head()
mydata.indexOutput:
RangeIndex(start=0, stop=45, step=1)
While reading the CSV file we have the option index_col using which we can set our index.
Eg. We are setting Employee name as our index
mydata = pd.read_csv("C:\\Users\\Employee_info.csv",\
index_col="Employee Name")mydata.indexOutput:
Index(['Aaditya', 'Aashima', 'Aishwarya', 'Anadi', 'Angad', 'Anita', 'Aparna', 'Archana', 'Ayesha', 'Damini', 'Deepak', 'Deepanshu', 'Fatima', 'Himani', 'Himanshu', 'Imran', 'Jenab', 'Lakshya', 'Mahesh', 'Manisha', 'Medha', 'Megha', 'Mehak', 'Monika', 'Pradeep', 'Prerna', 'Priyanka', 'Rajan', 'Rakesh', 'Raksha', 'Ramesh', 'Rashi', 'Ratan', 'Rohan', 'Ronak', 'Samarth', 'Sandeep', 'Sara', 'Siddhartha', 'Snophy', 'Suman', 'Sunita', 'Vaibhav', 'Ved', 'Zaheer'], dtype='object', name='Employee Name')
Multiple columns can make our index
We can also define multiple columns as our index in index_col by providing a list of columns to be set as index.
Eg. We are setting Employee name and their gender as index
mydata = pd.read_csv("C:\\Users\\Employee_info.csv",\
index_col=["Employee Name","Gender"])mydata.head()
Index need not be unique!
In the following command we are setting Department as our index.
mydata = pd.read_csv("C:\\Users\\Employee_info.csv",\
index_col="Department")We can sort our index as well using sort_index( )
mydata.sort_index()
Setting the index in an already existing dataset
Let us firstly read our CSV file
mydata = pd.read_csv("C:\\Users\\Employee_info.csv")Using set_index( ) we can set our index in already existing dataset.
data1 = mydata.set_index(["Employee Name","Gender"]).sort_index()data1.head(10)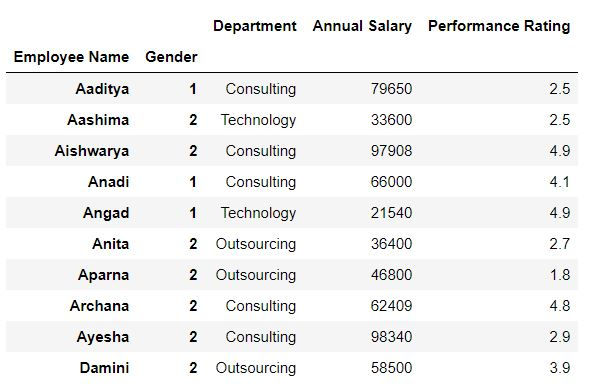
Filtering index
Task: In the above data filter for data for Employee Names starting from Aaditya till Angad.
We can filter the data indices using .loc function.
Since we require data from "Aaditya" till "Angad" thus we can write "Aaditya":"Angad"
data1.loc["Aaditya":"Angad"]
Let us filter for both the indices : Name and Gender
Task: Filter for rows for Aaditya , 1 till Archana,2 as index
For multiple indices to be filtered we define the 2 indices in a tuple and use a : colon to denote the ending point
In the code below, ("Aaditya",1) is the 1st tuple and ("Archana",2) is the 2nd tuple.
data1.loc[("Aaditya",1):("Archana",2)]
Resetting the index
We can also reset the index i.e. make them columns in our data using reset_index( ) function.
By default inplace = False, which means to save the changes we need to create a new dataset.
To make the changes in the original dataset we mention inplace = True
data1.reset_index(inplace = True)
data1.head()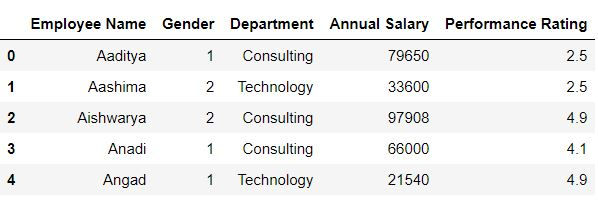



Comments